AI Agent
MCP
主要使用 Cline 以及 Copilot 的 Agent Mode 调用,主要采用 Github 以及其各自商城安装,使用 fetch 以及 file 阅读工具也能在 git clone 后让其自动阅读代码和 README 完成配置。工具基本采用 stdio 类型直接调用 node 或其他指令行阅读其输出,其印象较深的工具为mcp telegram, 可以直接采集群聊数据进行分析。
Dify Agent
至此对 Agent 这个概念还是一知半解,好奇 Cline 这类工具是怎么做到将不支持 Tool Calling 的 R1 等模型直接调用 MCP 等工具的。直到在探索 OCR Workflow 的过程中,发现了 Dify 官方有一个插件 langgenius/agent,通过 function 参数化后结合成的 Prompt 激活 Agent,让原本不支持的模型拥有调用工具的能力。
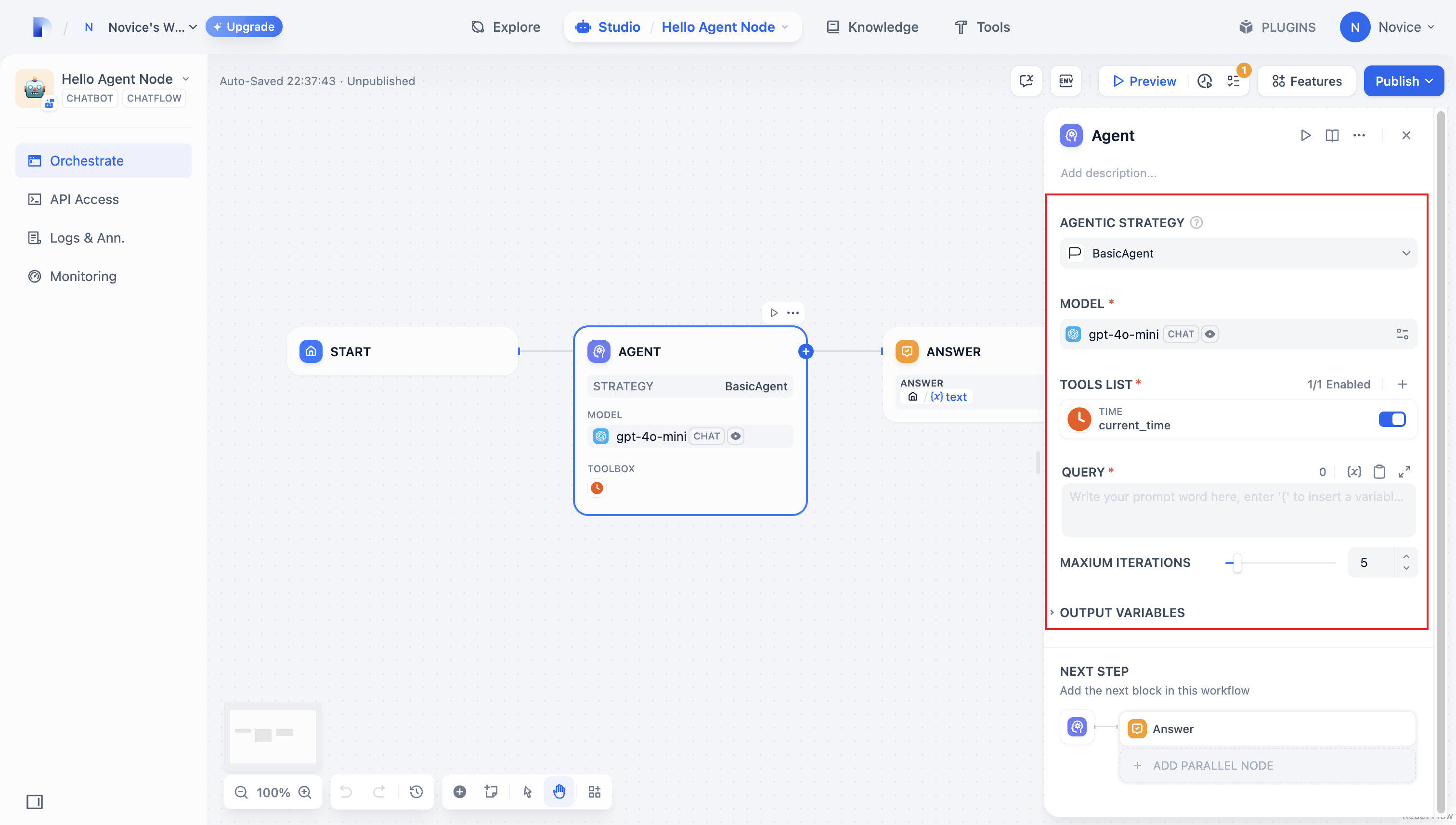
Dify 的 OpenRouter 以及 Groq 插件并没有做 Function Calling 的功能,但在 Workflow 中能够解锁使用工具以及持久化储存的能力。
Ollama
在测试 Agent 的初期采用的方案为 Qwen/Qwen3-Embedding-4B 进行矢量化 + 某本地模型的方案:
设置中 Ollama 插件配置如下:
Text Embedding
LLM
http://host.docker.internal:11434
对话
4096
最大 token 上限: 40960 或看模型参数
是否支持 Vision: 这里看模型本身是否支持,除了 gemma 以及 qwen2.5-vl 系列外基本都没
是否支持函数调用: 这里最重要的一步,针对 Ollama 以及工具调用能力欠佳的模型选否
只有选否后 langgenius/agent 插件才会自动启用 ReAct 模式赋予模型调用工具的能力。
经过测试后发现 Dify 的 Agent 应用中本地模型调用 Tool 后由于理解不佳以及性能较慢等问题,并不能完成翻译推送等任务
ollama create
以上为 ollama 默认模型地址,由于其 Library 并没有一些可用模型,因此需创建:
- 在 https://huggingface.co/ 上寻找
.gguf格式的模型用wget下载指以上目录
wget https://huggingface.co/Qwen/Qwen3-Embedding-0.6B-GGUF/resolve/main/Qwen3-Embedding-0.6B-Q8_0.gguf
- 创建
Dockerfile作为配置文件
- 创建模型
LM Studio
由于 Ollama 只能使用 gguf 格式,开启 server 后配合 OpenAI-API-compatible 插件可以直接在 1234 端口调用 MLX 基座的模型,也可以更改 LM Studio 的默认下载位置为 ollama 的默认模型位置方便调用。
OpenAI-API-compatible
但测试后发现,即使根据 BFCL Leaderboard 前三名的本地开源 8b 小模型进行测试还是会报错,因此直接采用 OpenAI-API-compatible插件调用 Groq 以及 OpenRouter 的方式,将函数调用改正为否后即可直接使用。体验下来 Groq 的 Qwen3-30b调用最快速但容易触发 Rate Limit,OpenRouter 的tngtech/deepseek-r1t-chimera:free模型能够将 R1 的精确与 V3 的效率融合为最佳。
Thoughts
Gradio以及直接用ollama的 Python 接口自己写一个对话界面是目前在算力足够的情况下建立本地 Agent 最有效的方式,Dify 的前端工作流操作类似于网页设计的 nocode, 在没有搞清楚需求的前提下将页面先设计出来实际上并不能满足复杂业务流程的需要,依旧得编程。qwen3:0.6b以及其他小模型均在复杂任务面前出现了问题,工具调用、翻译发布文章等依旧需要一些智力思维。Qwen3-30b级别的模型开始才能满足,并且体验发现在算力充足与不充足的情况下30b级别的模型也有智力差距,因此实际工作依旧需要用到大模型。QwenLM/Qwen2.5-VL以及gemma3在算力充足的情况下用作本地vision识别尚可。